source: http://cloudarchitectmusings.com/2013/06/24/openstack-for-vmware-admins-nova-compute-with-vsphere-part-1/
 [I've updated this series with information based on the new Havana release and changes in vSphere integration with the latest version of OpenStack. Any changes are prefaced with the word "Havana" in bold brackets]
[I've updated this series with information based on the new Havana release and changes in vSphere integration with the latest version of OpenStack. Any changes are prefaced with the word "Havana" in bold brackets]
One of the most common questions I receive is “How does OpenStack compare with VMware?” That question comes, not only from customers, but from my peers in the vendor community, many of whom have lived and breathed VMware technology for a number of years. Related questions include, “Which is a better cloud platform,” “Who has the better hypervisor,” and “why would I use one vs. another?” Many of these are important and sound questions; others, however, reveal a common misunderstanding of how OpenStack matches up with VMware.
The misunderstanding is compounded by the tech media and frankly, IT folks who often fail to differentiate between vSphere and other VMware technologies such as vCloud Director. It is not enough to just report that a company is running VMware; are they just running vSphere or are they also using other VMware products such as vCloud Director, vCenter Operations Manager, or vCenter Automation Center? If a business announces they are building an OpenStack Private Cloud, instead of using the VMware vCloud Suite, does it necessarily imply that they are throwing out vSphere as well? The questions to be asked in such a scenario are “which hypervisors will be used with OpenStack” and “will the OpenStack Cloud be deployed alongside a legacy vSphere environment?”
What makes the first question particularly noteworthy is the amount of code that VMware has contributed to the recent releases of OpenStack. Ironically, the OpenStack drivers for ESX were initially written, not by VMware, but by Citrix. These drivers provided limited integration with OpenStack Compute and were, understandably, not well maintained. However, with VMware now a member of the OpenStack foundation, their OpenStack team has been busy updating and contributing new code. I believe deeper integration between vSphere and OpenStack is critical for users who want to move to an Open Cloud platform, such as OpenStack, but have existing investments in VMware and legacy applications that run on the vSphere platform.
In this and upcoming blog posts, I will break down how VMware compares to and integrates with OpenStack, starting with the most visible and well know component of OpenStack – Nova compute. I’ll start by providing an overview of the Nova architecture and how vSphere integrates with that project. In subsequent posts, I will provide design and deployment details for an OpenStack Cloud that deploys multiple hypervisors, including vSphere.
OpenStack Architecture
OpenStack is built on a shared-nothing, messaging-based architecture with modular components that each manage a different service; these services, work together to instantiate an IaaS Cloud.
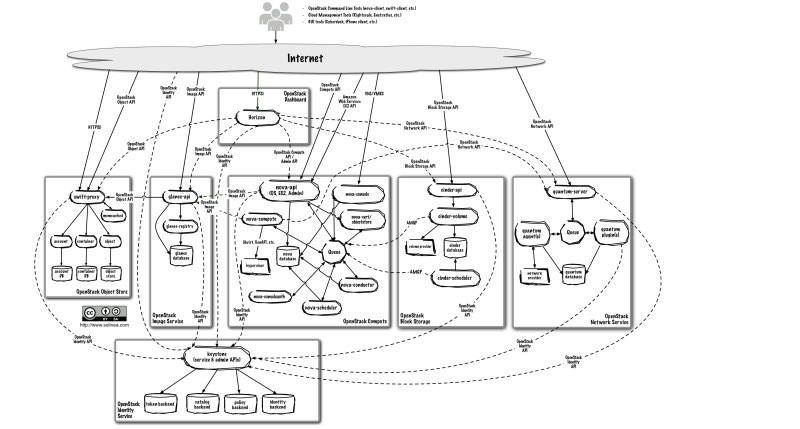
A full discussion of the entire OpenStack Architecture is beyond the scope of this post. For those who are unfamiliar with OpenStack or need a refresher, I recommend reading Ken Pepple’s excellent OpenStack overview
blog post and my “Getting Started With OpenStack”
slide deck. I will focus, in this post, on the compute component of OpenStack, called Nova.
Nova Compute
Nova compute is the OpenStack component that orchestrates the creation and deletion of compute/VM instances. To gain a better understanding of how Nova performs this orchestration, you can read the relevant
section of the “OpenStack Cloud Administrator Guide.” Similar to other OpenStack components, Nova is based on a modular architectural design where services can be co-resident on a single host or more commonly, on multiple hosts.
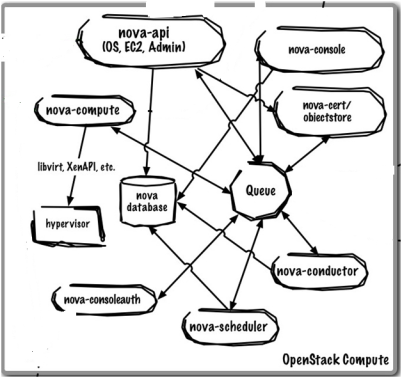
The core components of Nova include the following:
The nova-api accepts and responds to end-user compute API calls. It also initiates most of the orchestration activities (such as running an instance) as well as enforcing some policies.- The
nova-compute process is primarily a worker daemon that creates and terminates virtual machine instances via hypervisor APIs (XenAPI for XenServer/XCP, libvirt for KVM or QEMU, VMwareAPI for vSphere, etc.).
- The
nova-scheduler process is conceptually the simplest piece of code in OpenStack Nova: it take a virtual machine instance request from the queue and determines where it should run (specifically, which compute node it should run on).
Although many have mistakenly made direct comparisons between OpenStack Nova and vSphere, that is actually quite inaccurate since Nova actually sits at a layer above the hypervisor layer. OpenStack in general and Nova in particular, is most analogous to vCloud Director (vCD) and vCloud Automation Center (vCAC), and not ESXi or even vCenter. In fact, it is very important to remember that Nova itself does NOT come with a hypervisor but manages multiple hypervisors, such as KVM or ESXi. Nova orchestrate these hypervisors via APIs and drivers. The list of supported hypervisors include KVM, vSphere, Xen, and others; a detailed list of what is supported can be found on the
OpenStack Hypervisor Support Matrix.
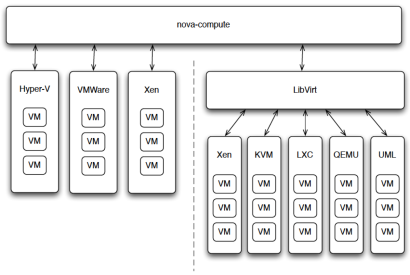
Nova manages it’s supported hypervisors through APIs and native management tools. For example, Hyper-V is managed directly by Nova, KVM is managed via a virtualization management tool called libvirt, while Xen and vSphere can be manged directly or through a management tool such as libvirt and vCenter for vSphere respectively.
vSphere Integration with OpenStack Nova
OpenStack Nova compute manages vSphere 4.1 and higher through two compute driver options provided by VMware – vmwareapi.VMwareESXDriver and vmwareapi.VMwareVCDriver:
- The vmwareapi.VMwareESXDriver driver, originally written by Citrix and subsequently updated by VMware, allows Nova to communicate directly to an ESXi host via the vSphere SDK.
- The vmwareapi.VMwareVCDriver driver, developed by VMware initially for the Grizzly release, allows Nova to communicate with a VMware vCenter server managing a cluster of ESXi hosts. [Havana] In the new Havana release a single vCenter server can manage multiple clusters.
Let’s talk more about these drivers and how Nova leverages them to manage vSphere. Note that I am focusing specifically on compute and tabling discussions regarding vSphere networking and storage to other posts.
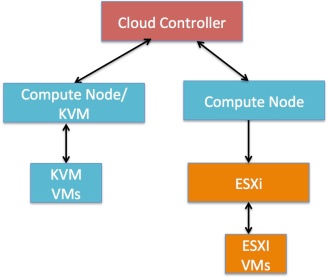
ESXi Integration with Nova (vmwareapi.VMwareESXDriver)
Logically, the nova-compute service communicates directly to the ESXi host; vCenter is not in the picture. Since vCenter is not involved, using the ESXDriver means advanced capabilities, such as vMotion, High Availability, and Dynamic Resource Scheduler (DRS), are not available. Also, in terms of physical topology, you should note the following:
- Unlike Linux kernel based hypervisors, such as KVM, vSphere with OpenStack requires the VM instances to be hosted on an ESXi server distinct from a Nova compute node, which must run on some flavor of Linux. In contrast, VM instances running on KVM can be hosted directly on a Nova compute node.
- Although a single OpenStack installation can support multiple hypervisors, each compute node will support only one hypervisor. So any multi-hypervisor OpenStack Cloud requires at least one compute node for each hypervisor type.
- Currently, the ESXDriver has a limit of one ESXi host per Nova compute service.
 ESXi Integration with Nova (vmwareapi.VMwareVCDriver)
ESXi Integration with Nova (vmwareapi.VMwareVCDriver)
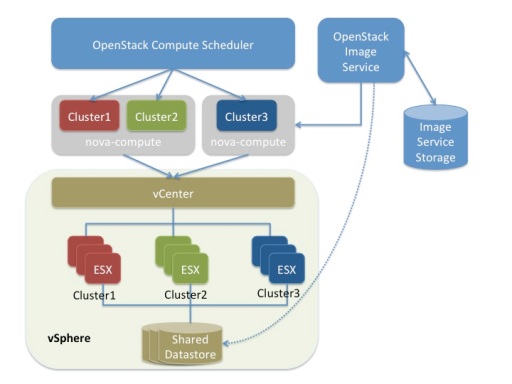
[Havana] Logically, the nova-compute service communicates to a vCenter Server, which handles management of one or more ESXi clusters. With vCenter in the picture, using the VCDriver means advanced capabilities, such as vMotion, High Availability, and Dynamic Resource Scheduler (DRS), are now supported. However, since vCenter abstracts the ESXi hosts from the nova-compute service, the nova-scheduler views each cluster as a single compute/hypervisor node with resources amounting to the aggregate resources of all ESXi hosts managed by that cluster. This can cause issues with how VMs are scheduled/distributed across a multi-compute node OpenStack environment.
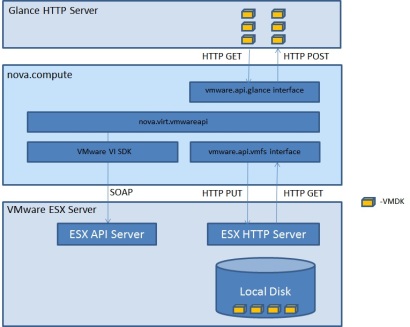
[Havana] For now, look at the diagram below, courtesy of VMware. Note that nova-scheduler sees each cluster as a hypervisor node; we’ll discuss in another post how this impacts VM scheduling and distribution in a multi-hypervisor Cloud with vSphere in the mix. I also want to highlight that the VCDriver integrates with the OpenStack Image service, aka. Glance, to instantiate VMs with full operating systems installed and not just bare VMs. I will be doing a write–up on that integration in a later post.
 [Havana]
[Havana] Puling back a bit, you can begin to see below how vSphere integrates architecturally with OpenStack alongside a KVM environment. We talk more about that as well in another post.
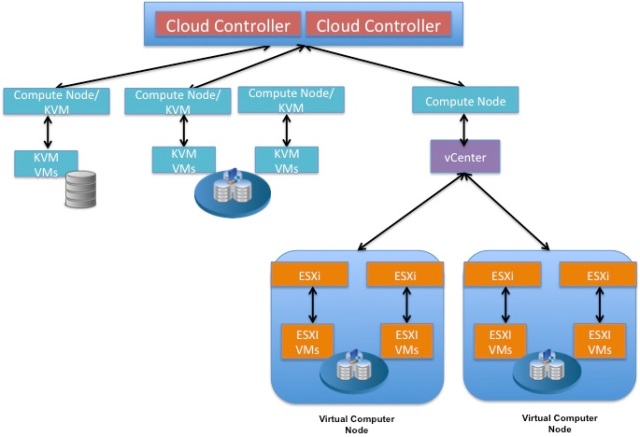
Also, in terms of physical topology, you should note the following:
- Unlike Linux kernel based hypervisors, such as KVM, vSphere with vCenter on OpenStack requires a separate vCenter Server host and that the VM instances to be hosted in an ESXi cluster run on ESXi hosts distinct from a Nova compute node. In contrast, VM instances running on KVM can be hosted directly on a Nova compute node.
- Although a single OpenStack installation can support multiple hypervisors, each compute node will support only one hypervisor. So any multi-hypervisor OpenStack Cloud requires at least one compute node for each hypervisor type.
- To utilize the advanced vSphere capabilities mentioned above, each Cluster must be able to access datastores sitting on shared storage.
- [Havana] In Grizzly, the VCDriver had a limit of one vSphere cluster per Nova compute node. With Havana, a single compute node can now manage multiple vSphere clusters.
- Currently, the VCDriver requires that only one datastore can be configured and used per cluster.
Hopefully, this post has help shed some light on where vSphere integration stands with OpenStack. In upcoming posts, I will provide more technical and implementation details.
See
part 2 for DRS,
part 3 for HA and VM Migration,
part 4 for Resource Overcommitment and
part 5 for Designing a Multi-Hypervisor Cloud.








