Databricks 에서 게제한 Spark 2.0 Technical Preview 글을 요약해 보았습니다.
spark 1.0 이 공개된 뒤 2년 만에 2.0 release 를 앞두고 있습니다.
Databricks 에서 공개한 Technical Preview 에서는 Spark 2.0의 3가지의 주요 특징을 소개하고 있습니다.
Easier, Faster, Smarter
- Easier
- 표준 SQL 지원
서브쿼리도 지원하는 새로운 Ansi-SQL 파서 적용 - DataFrame/Dataset API 통합
- Java/Scala 에서 DataFrame/Dataset 통합
- SparkSession
SQLConext 나 HiveContext 를 대체할 DataFrame API 를 위한 진입점 - 좀 더 간단하고 성능 좋은 Accumlator API
- 머신러닝 기반의 DataFrame
- R 을 위한 분산 알고리즘
- 표준 SQL 지원
- Faster
- 물리적 실행 영역을 다시 설계
- CPU 낭비시간 해소
- 가상함수 호출 시간
- CPU cache 나 memory 에 데이터를 쓰고 읽는 시간
- CPU 낭비시간 해소
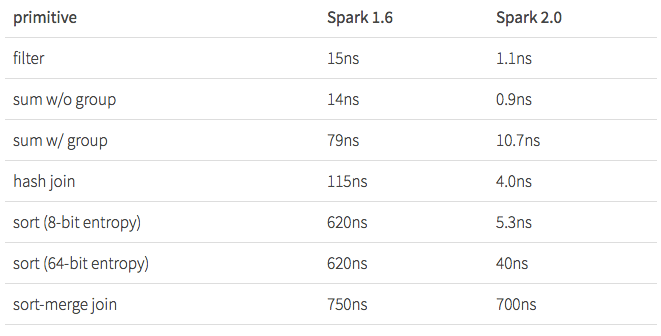
- 10억 건을 집계/Join 한 결과
- Parquet Scan 성능도 3배 이상 개선
- 물리적 실행 영역을 다시 설계
- Smarter
- Streaming engine 이상의 역할
외부 저장 시스템(예, RDBMS) 과의 연계, 비즈니스 로직을 잘 처리하는 능력 등
End-to End “Continuous application” (전체적인 흐름을 아우르는 Application) - Structured Streaming API + DataFrame/Dataset API
실시간 데이터 분석을 가능
- Streaming engine 이상의 역할
'BigData/Spark'에 해당되는 글 22건
- 2016.05.15Spark Streaming Resiliency(자동복구) (2)
- 2016.05.15Spark 2.0 Technical Preview
- 2015.08.20Learning Spark Chapter. 10 Spark Streaming
- 2015.07.31Learning Spark Chapter. 9 Spark SQL
- 2015.07.23Learning Spark Chapter. 8 Tuning & Debugging
- 2015.07.23Learning Spark Chapter. 7 Cluster 환경에서 수행하기
- 2015.07.23Learning Spark Chapter. 6 Spark 프로그래밍 고급편
- 2015.07.18Spark on YARN : Where have all the memory gone?
- 2015.07.17RDD persist() or cache() 시 주의사항
- 2015.07.17spark-submit 을 이용하여 Custom Argument 전달하기
아직은 Spark 2.0 이 preview package 이나 몇 주 내로 release 된다고 하니 기대가 됩니다.
Spark Streaming 과 DataFrame/Dataset API 를 잘 활용하면 실시간 분석을 쉽고 간단하게 할 수 있을 것 같습니다.
No comments:
Post a Comment