Abstract: Last year, I developed kiwenlau/hadoop-cluster-docker project, which aims to help user quickly build Hadoop cluster on local host using Docker. The project is quite popular with 250+ stars on GitHub and 2500+ pulls on Docker Hub. In this blog, I’d like to introduce the update version.
By packaging Hadoop into Docker image, we can easily build a Hadoop cluster within Docker containers on local host. This is very help for beginners, who want to learn:
How to configure Hadoop cluster correctly?
How to run word count application?
How to manage HDFS?
How to run test program on local host?
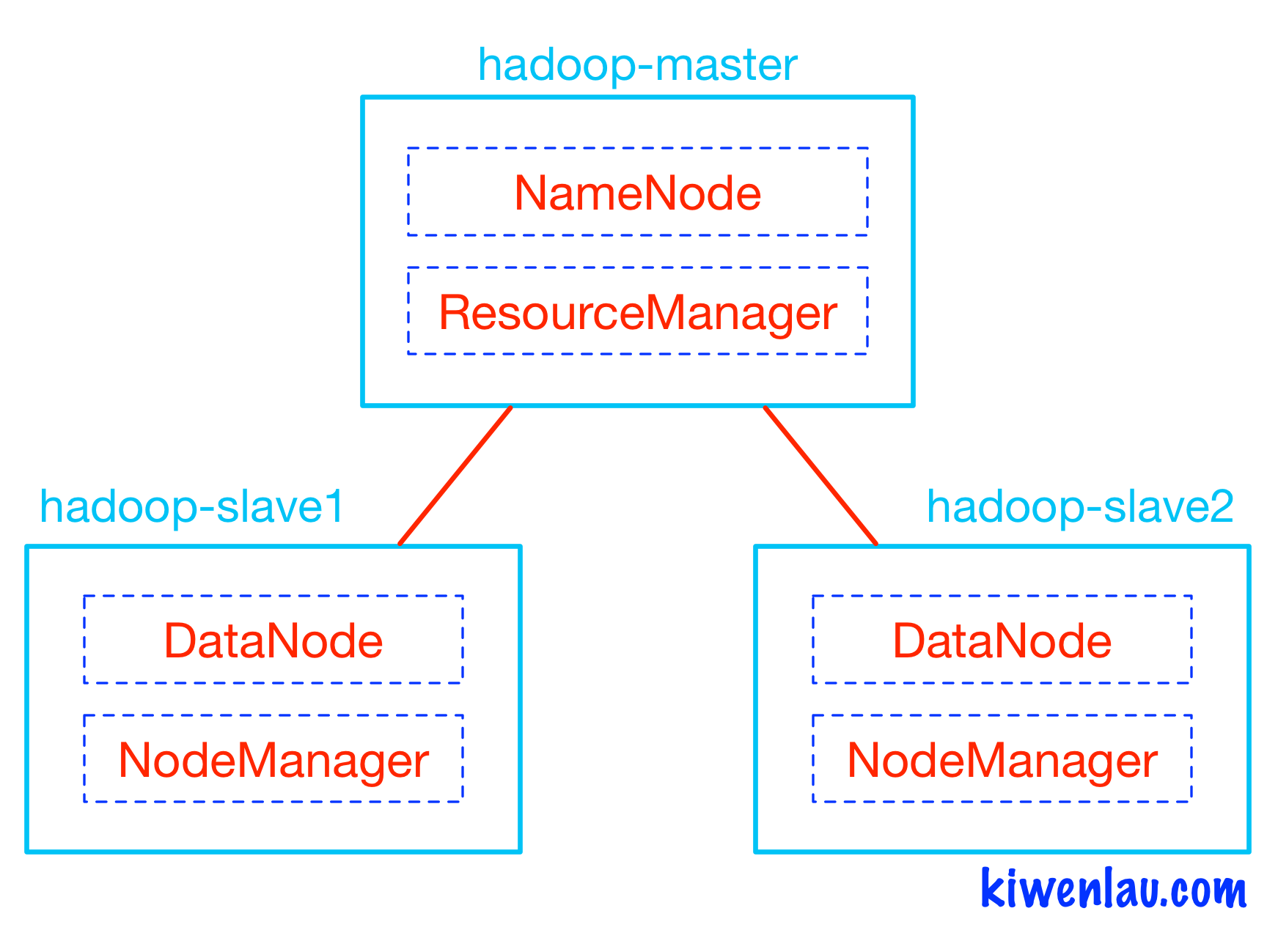
Following figure shows the architecture of kiwenlau/hadoop-cluster-docker project. Hadoop master and slaves run within different Docker containers, NameNode and ResourceManager run within hadoop-master container while DataNode and NodeManager run within hadoop-slave container. NameNode and DataNode are the components of Hadoop Distributed File System(HDFS), while ResourceManager and NodeManager are the components of Hadoop cluster resource management system called Yet Another Resource Manager(YARN). HDFS is in charge of storing input and output data, while YARN is in charge of managing CPU and Memory resources.
In the old version, I use serf/dnsmasq to provide DNS service for Hadoop cluster, which is not an elegant solution because it requires extra installation/configuration and it will delay the cluster startup procedure. Thanks to the enhancement of Docker network function, we don’t need to use serf/dnsmasq any more. We can create a independent network for Hadoop cluster using following command:
sudo docker network create--driver=bridge hadoop
By using “–net=hadoop” option when we start Hadoop containers, these containers will attach to the “hadoop” network and they are able to communicate with container name.
No comments:
Post a Comment