source: https://a-misra.com/2016/10/02/oracles-big-data-analytics-platform-for-data-scientists/
Oracle’s Big Data & Analytics Platform for Data Scientists
I work for Oracle, helping businesses realize the potential of data science, big data and machine learning to grow their revenues, minimize their costs and expand new opportunities to leap-frog their competition. Which means working with some amazing folks from different parts of businesses and across industries. Invariably I’m asked – So, what does Oracle offer in the space of data science and machine learning on Big Data?
Lets leave aside the machine learning and optimization solutions embedded within different Oracle products, and just focus on the platform pieces for Big Data and Analytics for today. Lets also ignore for the moment the data management questions around security, encryption and integration that are important and chiefly the concerns of the IT department. Lets focus only on what it offers for data analysts and data scientists.
Oracle’s Big Data & Analytics Platform enables data science and machine learning at scale by taking the best that open-source offers, putting it together as an engineered solution and adding capabilities and features where open-source falls short.
Oracle Big Data Cloud Service (BDCS) is essentially Hadoop/Spark in a “Box” (or rather a number of dedicated cloud based machines connected with a 40Gb/sec InfiniBand fabric making network IO between cluster nodes very fast). It runs Cloudera Enterprise version of Hadoop with engineered hardware optimized for speeding up the analytics. Analysts can use Python, R, Scala and Java for data manipulation, analytics and machine learning using open source libraries such as SparkML. Python users such as myself can use open-source libraries (e.g. numpy, scipy, pandas, scikit-learn, seaborn, folium) inside Jupyter notebooks via PySpark kernel for operating on distributed datasets.
Out of the box, R users don’t get all the benefits of SparkML, so Oracle R Advanced Analytics for Hadoop (ORAAH) addresses that gap, giving R users access to SparkML implementations of machine learning algorithms. In addition ORAAH’s own implementation of Linear Regression, Generalized Linear Models and Neural Networks are faster and more efficient than the open-source implementations within SparkML. In experiments run by Marcos Arancibia‘s team, ORAAH’s LM model training was 6x-32x faster than SparkMLlib. Similarly GLM models trained by ORAAH were 4x -15x faster than SparkMLlib. More importantly, ORAAH continues to scale linearly despite memory constraints, where as SparkMLlib just fails.

ORAAH is available for on-premise (BDA) and the cloud (BDCS).
But not everyone can code or should have to code to transform and explore data in Hadoop. Oracle Big Data Discovery (BDD) provides “citizen data-scientists” and data analysts with interactive way to find, transform and visually discover patterns or relationship within the data stored in Hadoop. It works by keeping a sample of the data in Hadoop in-memory, automatically generating graphs that describe the shape of that attribute, and allows users to interactively manipulate that data.
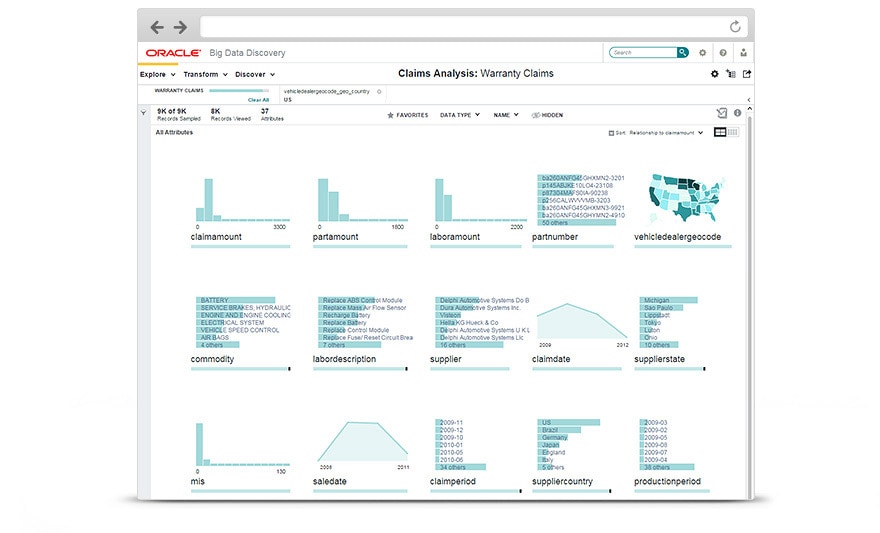
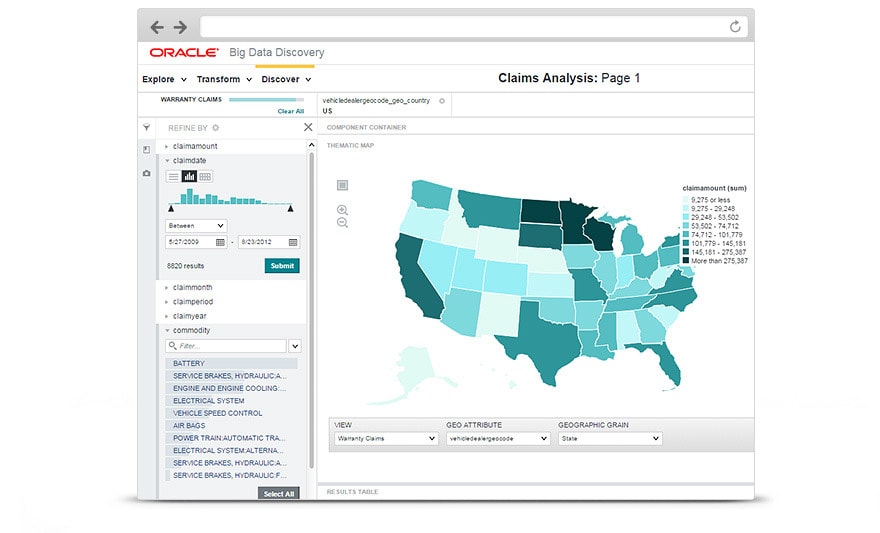
Once the analyst is comfortable with the transformations, he or she can apply them to the full dataset with a click of a button. It is a very nice tool for data analysts and data scientists alike in preparing a dataset before switching to Jupyter or RStudio to use the distributed machine learning algorithms in Spark or ORAAH.
- BDD: Intro
- BDD Demo: Warranty Claim
- BDD Demo: NYC Taxi Rides
- BDD Shell
- BDD Driven Insights: Black is the new Yellow
Data isn’t always in a tabular form, nor does it make sense to analyze it that way. The Spatial component of Oracle Big Data Spatial & Graph (BDSG) scales up the analysis of images and geo-spatial data using Hadoop and OpenCV with a Java interface. Just last week I finalized a patent application on a method to automate the alignment and analysis of aerial and satellite imagery to known structures, that I had prototyped earlier this year. For one potential customer wanting to scale their operations to cover 100,000 acres of agricultural properties no longer requires them to hire a team of 40 GIS specialists and making them work round to clock to keep up with the volume of imagery expected each week.
The Graph component of BDSG provides an in-memory graph engine and algorithms for fast property graph analysis. The in-memory graph engine can handle 20-30 billion edge graphs on a single node, scale out to multiple nodes as it expands beyond the limits of a single node, and perform 10-50x faster than other graph engines for finding communities, optimal paths and even product recommendations.
- BDSG Intro
- BDSG Spatial Features Overview
- Graph Analytics for Businesses
- Recommendations using Graph Analytics
- Detecting anomalies with Oracle Big Data Spatial and Graph
Analysts that have been using Oracle Advance Analytics (OAA) as part of the Oracle Databases to train machine learning models within the database or using R, can continue to use the same interface while bringing in data from Hadoop or NoSQL Databases via Oracle Big Data SQL. Big Data SQL pushes the predicate (i.e. query processing and filtering) to Hadoop or NoSQL Databases and pulls across only the smaller filtered dataset to the relational Database. This allows analysts to user SQL, Oracle Data Miner or R, while manipulating and joining datasets in Hadoop and Database.
- Big Data SQL Intro
- Big Data SQL Data Sheet
- Oracle Advance Analytics and Big Data SQL Demo
- Real-time Big Data Analytics @ StubHub
Once the analysis is done, now comes time to tell the story. Oracle Data Visualization (DV) is an interactive data visualization and presentation platform as a desktop application or a cloud service, letting the business intelligence, analysts and scientists reveal the story hidden within the data visually.
- Data Visualization Intro
- Data Visualization Marketing Demo
- Data Visualization Social Media Campaigns Demo
There are also a number of things that have been announced at Oracle Open World 2016, and coming soon. One of the most exciting for data science is the Big Data Cloud Service – Compute Edition (BDCS-CE). It is an on-demand elastic compute Hadoop/Spark cluster, allowing data scientists to spin up clusters as needed, scaling it up as needed and tear them down afterwards. For an analysts perspective, it is a perfect environment to sandbox ad-hoc queries and experimentation, before operationalizing these as analytics pipelines. There is also the Event Hub Cloud Service that provides a Kafka-based streaming data platform.
No comments:
Post a Comment